Microsoft have yet recently announced “Service Degradation” on Exchange Online- a hosted email service for businesses.
This follows closely after the issues with Microsoft 365 and Teams back in January. I think we can all agree that incidents and crashes like these are always common on almost every software, website and line of code on the internet.
However, the issue stems from when it happens with a tech giant like Microsoft, as one small issue still affects many people.
If you want more details on the incident, then look no further than this blog as we outline it in brief summary.
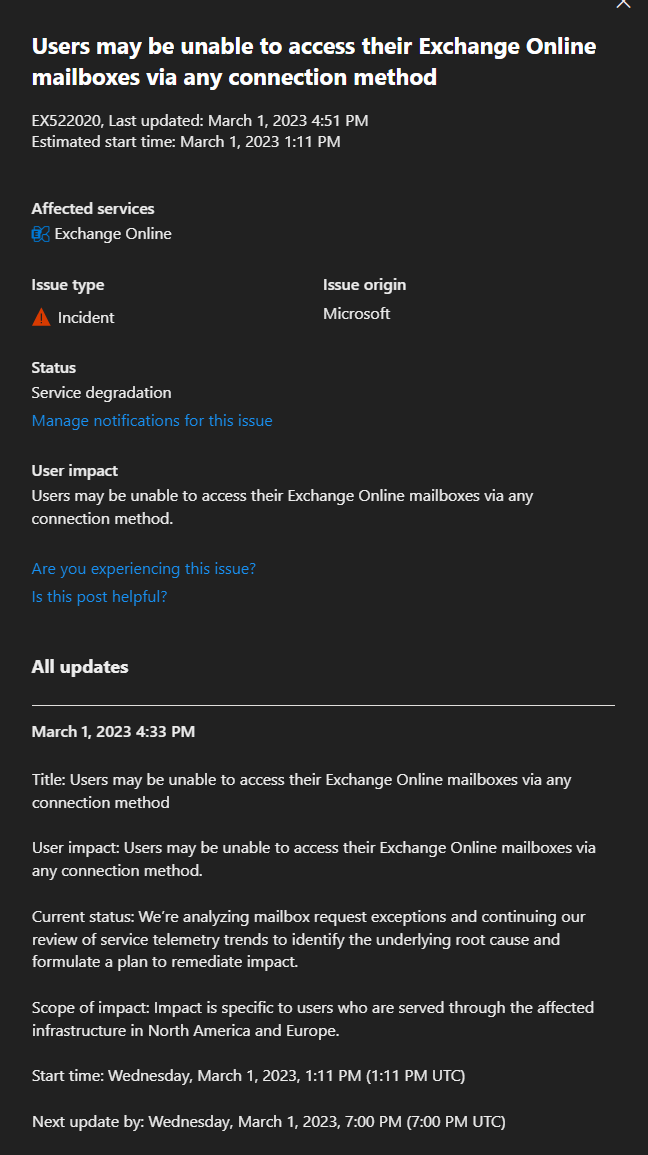
Microsoft first tweeted about this at 4:56 pm, Wednesday, the 1st of March. Microsoft’s official report was that some users was unable to access mailboxes through any connection method.
The specific error message that users got was:‘550 5.4.1 Recipient address rejected: Access denied’. Additionally, the scope of the incident spun out across North America and Europe… that’s a lot of affected inboxes!
Here is the direct message from Microsoft themselves to the affected users:
This issue continued for hours, with numerous Tweets from Microsoft being sent out to inform users of progress with fixing the incident. However, this was fully fixed at 8:59 pm.
Across the Tweets that Microsoft sent, a few of them included details about the strategy for fixing the issue which brings us onto our next point, how was this fixed?
According to the reports from Microsoft, through their Twitter account, we can speculate that Mitigation of the issue was the first priority, yet it still took a few hours to reach that point.
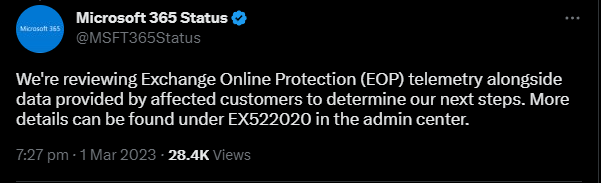
As you can see, this Tweet was sent at 7:27 pm which suggests that all the hours up until that point were spent on researching the issue, it’s impacts, etc.
Specifically, the Tweet mentions the plan to review Exchange Online Protection (EOP) telemetry, which is a fancy way of saying- troubleshooting performance data.
This line of thinking was clearly successful for Microsoft as in just a short time, this Tweet was released:
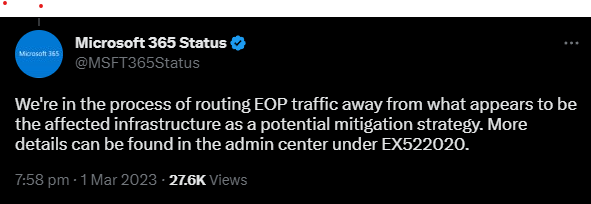
As evident in this Tweet, the reason for this incident is explained to be due to “affected infrastructure”, specifically for EOP.
This is the strength and weakness of most cloud-based software’s as issues/incidents seem to crop up a lot more commonly, yet they get fixed much faster in return.
Soon after this tweet, Microsoft confirmed the success of this Mitigation strategy then resumed to reach out to all affected users in case some issues still persisted.
A good takeaway from this incident is to appreciate the “ripple-effect” that even the smallest issues in IT can cause, ranging from slightly aged IT infrastructure in a business network, to a modest glitch in a system. The reality is that, those “small issues” can become quite large ones if left unchecked.
This also emphasises the need for a business to Manage Their IT in-house or externally.
This concludes our blog on Microsoft’s latest incident, we hope you’ve liked this short summary. Be sure to stay up to date on the latest IT news and informational articles. Thanks for reading!

